Когда я изучаю новый язык, то после базового изучения синтаксиса пробую решать на нём выдуманную задачку, взятую из игры James Bond Jr для платформы NES. Попробовал решить её на Nim и сравнить с решениями на других языках.
В этой игрушке в первой зоне сын известного спецагента Джеймса Бонда должен деактивировать 5 ракет главзлодея.
Чтобы “выключить” ракету, необходимо решить головоломку:
Заданы исходное поле из разноцветных клеток и целевая позиция,
в которую надо перевести поле, сдвигая любую строку или столбец.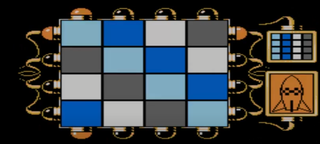
(Первая, самая простая, версия загадки)
Задача хороша тем, что несмотря на кажущуюся простоту, требует немного задуматься в более сложных вариантах, как при решении руками, так и при составлении алгоритма – простое построение дерева решения в лоб для одной из головоломок может занять очень много времени.
Предыдущие эксперименты:
(2009) Python in imaginary world - первая попытка решить задачу на Python, скрины и решения всех 5 головоломок.
(2015) Scala in imaginary world - решение на Scala после прохождения курса Мартина Одерски на Coursera.
Отдельно исходники решения:
Python (портировал со второй на третью версию)
Scala
В решениях оставлена только самая сложная версия головоломки: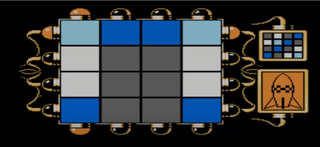
source = [1,2,2,1, 3,4,4,3, 3,4,4,3, 2,4,4,2]
target = [4,3,4,2, 3,1,2,4, 4,2,4,3, 2,4,3,1] ##4Критерии выбора языка#
Python когда-то заинтересовал тем, что в нём можно было очень быстро сделать прототип того, что хочешь, причём на высоком уровне абстракции. При этом начинать писать на нём полезные вещи можно буквально через несколько дней после изучения, а с помощью большого набора готовых библиотек можно отыскать быстрый способ решить конкретную задачу минимальным количеством кода.
Но через несколько лет захотелось найти языки, которые были бы лучше по какому-либо из критериев:
- со статической типизацией
Иногда мешает, что ошибки типов находятся только в рантайме. Особенно если нужно модифицировать функцию, возвращающую различными способами список из 3-4 элементов сложных типов. Это можно вылечить культурой разработки (тесты, аннотации типов), но хочется подобрать язык, который защитит от таких ошибок совсем (ну или хотя бы чуть-чуть лучше).
- с более выразительным синтаксисом
Дзен питона - There should be one— and preferably only one —obvious way to do it. При этом, на нём не очень удобно писать в функциональном стиле, лямбда-функции местами ограничены. Изредка, но хочется немного более свободного способа выражения мыслей.
- с возможностью собирать нативный код
Язык с виртуальной машиной типа Python можно запаковать в исполнимый файл без зависимостей только вместе с этой виртуальной машиной. Но случае распространения программ конечным пользователям не всегда удобно, что небольшая утилита или скрипт тянет за собой тонны кода интерпретатора и библиотек. Иногда хочется иметь возможность получить небольшой исполнимый файл, который только лишь делает необходимую работу.
- более быстрый
Изредка, нужно чтобы небольшая утилита при этом была ещё и быстрой. При использовании скриптовых языков в этом случае принято переходить на C.
- максимально кроссплатформенный
Python хорош для работы в Windows/Unix/macOS, но использовать его на мобильных платформах (Android/iOS) сложно. Не то чтобы невозможно, но скорее нецелесообразно. В этом случае снова логично переходить на C - iOS поддерживает C/C++ в своих ObjectiveC/ObjecticeC++ вставках, Android имеет компилировать нативный код через NDK, также можно собрать его с помощью Emscripten для запуска в браузере.
- кросс-языковое использование
В идеале, должен быть способ использовать программу или утилиту из других языков различными способами. В этом случае снова самым удобным является код на C, собранный в библиотеку - почти все языки позволяют вызвать такой код. Если же вы хотите выполнить Python скрипт из своей программы, то не всегда понятно, что делать в этом случае - встроить ли в программу интерпретатор python и нужные для скрипты библиотеки? полагаться на то, что Python уже есть в окружении и вызвать его как системный процесс, прочитав его поток вывода? Или вообще завернуть всё окружение в docker?
Scala обладает первыми двумя качествами (статически типизированная и выразительная), но при этом нацелена на экосистему Java, т.е. обладает проблемами там, где хочется связи с не Java-миром, а также компактности и скорости.
Nim#
Автор Nim декларирует то, что он соответствует всем требуемым критериям, в основном из-за того, что язык компилируется в C/C++-код, а значит - легко взаимодействует с ним, и компилируется там, где и эти языки (т.е. практически на любой платформе). Поэтому захотелось затестировать его и сравнить для себя с Python.
Первая попытка решения:
Nim
Особенности синтаксиса#
- Поддержка спецсимволов "из коробки"
Можно вывести ответ в чуть более удобной форме
type
Dir = enum →, ←, ↑, ↓, NOP
(NOP,0): [1, 2, 2, 1, 3, 4, 4, 3, 3, 4, 4, 3, 2, 4, 4, 2]
(→,2): [1, 2, 2, 1, 3, 4, 4, 3, 3, 3, 4, 4, 2, 4, 4, 2]
(←,0): [2, 2, 1, 1, 3, 4, 4, 3, 3, 3, 4, 4, 2, 4, 4, 2]
(↓,3): [2, 2, 1, 3, 3, 4, 4, 4, 3, 3, 4, 2, 2, 4, 4, 1]
(←,0): [2, 1, 3, 2, 3, 4, 4, 4, 3, 3, 4, 2, 2, 4, 4, 1]
(←,2): [2, 1, 3, 2, 3, 4, 4, 4, 3, 4, 2, 3, 2, 4, 4, 1]
(↑,1): [2, 4, 3, 2, 3, 1, 4, 4, 3, 4, 2, 3, 2, 4, 4, 1]
(←,0): [4, 3, 2, 2, 3, 1, 4, 4, 3, 4, 2, 3, 2, 4, 4, 1]
(←,2): [4, 3, 2, 2, 3, 1, 4, 4, 4, 2, 3, 3, 2, 4, 4, 1]
(↑,2): [4, 3, 4, 2, 3, 1, 2, 4, 4, 2, 4, 3, 2, 4, 3, 1]- Нельзя использовать итераторы вне for-цикла
#sort of magic - iterator can be used only with `for`, but it can be wrapped to var sequence, and after calculation
proc generateProduct[T,U] (aa:T, bb:U) : auto = (var x = newSeq[tuple[a:type(aa[0]), b:type(bb[0])]](); for pair in product(aa, bb) : x.add(pair); x)Вся выглядящая магией функция generateProduct - это обёртка вокруг итератора product, чтобы можно было использовать его в произвольном коде, а не только внутри for. Скорее всего подобное можно завернуть в макрос, которым можно трансформировать любой итератор в функцию, но это уже за рамками первой программы.
- В стандартной библиотеке нет нужных комбинаторных функций
Функция product взята из библиотеки itertools. Не очень страшно, скорее всего стандартная библиотека будет расширена в новых версиях языка.
- Выразительность системы типов
Ещё раз посмотрим на код generateProduct. В ней есть интересный способ записи информации о типах. Тип переменной x тут можно прочитать как:
Последовательность из пар,
в которых тип первого элемента пары: "такой же, как первый элемент массива aa",
а тип второго элемента пары: "такой же, как первый элемент массива bb".Это неудобочитаемо, мы не описали явно, что aa и bb - массивы, но тем не менее компилятор проверит, что это так , когда будет выводить тип x (точнее даже - ему будет достаточно того, что для типов aa и bb можно обратиться к первому элементу и взять его тип).
Возможность потребовать от компилятора вывести тип в любом месте кода напоминает мне Lisp, хотя Goran Krampe в серии статей про Nim утверждает, что это - наследие Smalltalk.
Более стандартный способ выражения типов, в котором явно сказано что aa и bb - это массивы из элементов какого-то типа:
#sort of magic - iterator can be used only with `for`, but it can be wrapped to var sequence
proc generateProduct[T,U] (aa:openArray[T], bb:openArray[U]) : seq[tuple[a:T, b:U]] =
(var x = newSeq[tuple[a:T, b:U]](); for pair in product(aa, bb) : x.add(pair); x)- Синтаксис стимулирует разбивать код на от отдельные файлы
Одна из идиом языка - определить свои типы и “доопределить” стандартные функции, чтобы они работали с новыми типами:
type
FieldPathInfo = tuple[rate: int, v:Field, prev:Field, level:int, operation: OperationCode]
proc `<`(a : FieldPathInfo, b : FieldPathInfo) : auto = a.rate > b.rate #определяем какой из типов "больше"
#хоп, теперь можно позвать opened.sort() - сортировка будет использовать этот оператор
var opened = newSeq[FieldPathInfo]()
opened.sort()Раз уж типы и функции, работающие с этими типами, нельзя связать в класс, то любому нормальному программисту захочется отделить их в отдельный файл.
Код по выразительности сопоставим с Python, система типов позволяет не только аннотировать тип, но и написать код зависимости между типами, который проверит компилятор. Удобно, что этот код - такой же код на Nim, как и остальная программа, а не отдельный язык (как в случае с C++).
Кроссплатформенность#
Руководство к компилятору выдаёт все нужные ключи, чтобы траслировать код из Nim в C, C++, Objective C и JavaScript (тут, правда, отмечают, что проще транслировать полученный C код в JavaScript с помощью Emscripten - это более надёжный вариант, чем nim->js).
Я протестировал сборку под macOS, но не смотрел сборку для ios/android - “скелет” программы требует намного больше усилий, чем просто компиляция из командной строки, так что тут Nim тоже находится примерно на уровне Python.
Скорость#
Моя старая программа на Python находит решение на моём компьютере за ~2-3 секунды. Версия на Nim работает ~4 секунды.
В первую очередь, конечно, надо просто включить оптимизацию :)
nim -d:release --opt:speed c james_bond_nim.nimС такими ключами программа работает уже ~1-2 секунды, что, конечно, опережает Python-версию, но разница между компилируемым и интерпретируемым языком должна быть ощутимее.
Поэтому я всё-таки изучил Nim ещё немного, чтобы понять, что не так. Основная причина тормознутости в том, что базовый тип языка seq - неподходящая структура данных, так как, в отличие от базового list в Python, выполняет лишние копирования. Забавно, что даже с учётом этого, оптимизированная Nim версия выполняется быстрее. Более подходящая структура - DoublyLinkedList.
Также для красоты сделал тип для более удобной работы с открытым списком – объединил в структуру связанный список и хеш-таблицу для кеширования значений (хеш-таблица есть и в python-версии):
OpenList = object
opened : DoublyLinkedList[FieldPathInfo]
openedLen : int
hashes : HashSet[Field]Убрал зависимость от библиотеки itertools:
#there is no product in standart library
iterator product[T, U](s1: openArray[T], s2: openArray[U]): tuple[a: T, b: U] =
for a in s1:
for b in s2:
yield (a, b)
proc generateProduct[T,U] (aa:openArray[T], bb:openArray[U]) : seq[tuple[a:T, b:U]] =
(var x = newSeq[tuple[a:T, b:U]](); for pair in product(aa, bb) : x.add(pair); x)Для теста “кросс-язычности” экспортировал функцию поиска в Python:
import nimpy
proc main() : Field {.exportpy.}И определил свою функцию конвертации в строку для вывода на экран:
proc `$`(op: OperationCode) : auto = "(" & $op.dir & "," & $op.line & ")"В результате замены seq на DoublyLinkedList программа начала выполняться за доли секунды - в десятки раз быстрее аналогичной Python-версии.
Для выполнения точных замеров нужно конечно сгенерировать множество входных данных и исследовать скорость на них, но мне было достаточно того, чтобы добиться измеримых “на глаз” показателей скорости.
Ещё одна из возможностей Nim - перенос выполнения кода полностью на момент компиляции, но воспользоваться ей сходу не получилось, так что она тоже находится за рамками первой программы после изучения языка.
**update**
Третьим заходом всё-таки выполнил решение в полностью в compile-time:
Compile-time версия решения
Основные изменения - изменить let на const в определениях переменных (последовательно в функции решения и ещё 2 зависимых от него определениях глобальных переменных):
#let answer = solve().reconstructPath() //run-time
const answer = solve().reconstructPath() //compile-timeДополнительно оказалось, что функция shuffle из библиотеки random не умеет работать в compile-time - это проблема библиотеки, но решение нашлось достаточно быстро - переписанная для использования в compile-time версия:
var rng {.compileTime.} = initRand(0x1337DEADBEEF)
proc compileTimeShuffle[T](x: var openArray[T]) =
for i in countdown(x.high, 1):
let j = rng.rand(i)
swap(x[i], x[j])Компилятор выполняет вычисления медленнее, чем скомпилированная программа, и собирает программу за минуту-полторы, вдобавок просит добавить ему ключ, позволяющий продлить ему время на вычисления:
nim c --maxLoopIterationsVM:100000000 nim_james_bond_compile_time.nimОбычно compile-time вычисления делаются для более простых вещей, однако здесь интересна именно сама возможность в один проход собрать программу, которая выдаёт ответ в виде строчки:
echo("ответ, уже посчитанный компилятором")Итоги#
Nim на удивление хорошо подходит по тем критериям, которые я искал изначально – статически типизируемый, выразительный, быстрый, кроссплатформенный и легко связываемый с другими языками.
Я пока не изучил его продвинутые возможности – систему макросов, возможности по подключению бекэндов, использования нативных библиотек на других языках, выполнение кода во время компиляции - каждая из них выглядит интересной.
Недостатки языка также очевидны – у него пока нет продвинутой экосистемы тулзов, за ним не стоит большая корпорация, и он достаточно молод (видны некоторые изменения синтаксиса в документации по сравнению с актуальной версией компилятора, в стандартной библиотеке как будто не хватает каких-то нужных для удобной работы функций).
Но Nim обладает одним из самых важных свойств для языка программирования - на нём приятно писать.