Традиционный пайплайн создания анимированного персонажа для игр выглядит примерно так:
📍 Выбор референса
📍 Эскиз и поиск силуэта/формы
📍 Одна или несколько итераций детализации
📍 Рендер (закрашивание)
📍 Добавление затенений/освещения
📍 Нарезание на слои (для cut-off или скелетной анимации)
📍 Создание скелета и vertex-painting/прикрепление частей к костям (для скелетной анимации)
📍 Анимация (для покадровой или смешанной анимации — дорисовка отсутствующих кадров/частей)

Виды 2D анимации
2D Animation & Art to a Game — Full Export Workflow (Inkscape → Blender → Godot)
ИИ пайплайн
Я решил попробовать, что умеют нейронки, с ними процесс получается вывернутым наизнанку.
I Made Street Fighter in 4 Hours with AI - Complete Tutorial — автор тут показывает основные шаги пайплайна, собранные в платном веб-интерфейсе. То же самое можно получить пользуясь python скриптами и прямым доступом к нейронкам, не доплачивая за арбитраж токенов сторонним разработчикам. Я добавил еще пару шагов от себя, для улучшения качества, сжатия атласа, и возможности перехода от покадровой анимации к cut-out или скелетной.
- Генерация изображения
- Генерация анимации
- Убирание цвета фона
- Коррекция кадров анимации
- Выделение фич
- Перепаковка атласа
- Удаление похожих кадров фич
Генерация изображения#
Генерируем изображение по текстовому описанию, опционально добавляя референсное изображение или позу.
Здесь можно воспользоваться
📍 ChatGPT + DallE
📍 Gemini + Nana Banana
📍 Midjourney
📍 ComfyUI + Control.Net + SDXL + дообучение под стиль (бесплатные, хуже базовая модель, но больше доступных инструментов)

ChatGPT. Нарисуй в таком же стиле волшебника (в качестве референса взят рыцарь в похожем мультяшном стиле с pinterest). Фон должен быть однотонный ярко-зеленый
То, что фон получается не совсем однотонный — нормально, его всё равно придётся убирать нейронкой. Но возможно именно зелёный, некоторые модели обученны именно на этом цвете.
Генерация анимации#
Из того, что я имеется на сейчас, лучший способ покадровой анимации изображения — сгенерировать короткой видео. Модели:
📍 Grok Imagine. Через веб-интерфейс доступно видео от 6 секунд, но это слишком много. Через sdk можно сгенерировать 1-2 секунды. На практике выходит, что если ему не хватает кадров, например, при анимации лица, то он делает “блендинг” между 2 кадрами лица, что выглядит ужасно. Это лечится увеличением длины. Слишком большая длина ухудшает стабильность, и последний кадр возврата в исходную позицию не похож на первый. Нужно подобрать длину под стиль (чаще всего 1-2 секунды).
Цена - 0.05$ за секунду
Альтернативы:
📍 Nana banana. Примерно те же правила, что и с Grok
📍 Wan. Можно использовать дообучение (примерно на нескольких десятках-сотен анимаций, и несколько сотен долларов на аренду видеокарты. Пример результата aaaa_Aa под пиксел-арт). Про дообучение — пока не разбирался детально, выглядит очень перспективно.
Кроме генерации через видео есть и другие способы (например, через генерацию позы + предыдущего референсного кадра), но они выглядят сложнее, и не масштабируются быстро на анимацию в 20-40 кадров, и требуют более сложного тюнинга. Из плюсов — входные данные о позе могли бы быть использованы дальше
Перед генерацией нужно расширить изображение, что хватило место под анимацию. Также нужно рассчитать пропорции, чтобы размер подходил под параметр соотношения сторон, указанный при генерации модели
Код генерации для Grok:
import os
import xai_sdk
import base64
client = xai_sdk.Client(api_key="КЛЮЧ")
with open("wizzard.png", "rb") as f: # или .jpg, .jpeg и т.д.
image_bytes = f.read()
image_base64 = base64.b64encode(image_bytes).decode("utf-8")
image_data_uri = f"data:image/png;base64,{image_base64}"
response = client.video.generate(
image_url=image_data_uri,
prompt="волшебник атакует посохом, колдует магию, атака направлена вправо. no vfx",
model="grok-imagine-video",
duration=2,
aspect_ratio="4:3",
resolution="480p",
)
print(response.url)
# забираем mp4 файл“no vfx” здесь — магическая часть промпта, чтобы ии не дорисовал к посоху искры или огонь (в играх это обычно добавляется системами частиц или отдельной анимацией)
Получается примерно такое видео:
Дальше режем видео на кадры ffmpeg-ом.
Убирание цвета фона#
Видео на сохраняет альфа-канал, поэтому следующая задача — устранить влияние зеленого фона, который сейчас подмешан в мягкие края изображения, и полупрозрачные части.
CorridorKey — лучшая модель для этого (особенно понравилось их демо-видео). Модель принимает на вход приблизительные данные об альфа канале, которые получаются с помощью других нейронок:GVM/ VideoMaMa для генерации приблизительного alpha-hint (я брал первую, так как вторая весит 40 гб и дополнительно требует Stable diffusion базовую модель еще в 2.5 гб)
EZ-CorridorKey - GUI обёртка. На каком то шаге еще использует SAM-2, модель от Meta для уточнения силуэта от примерного до более точного.
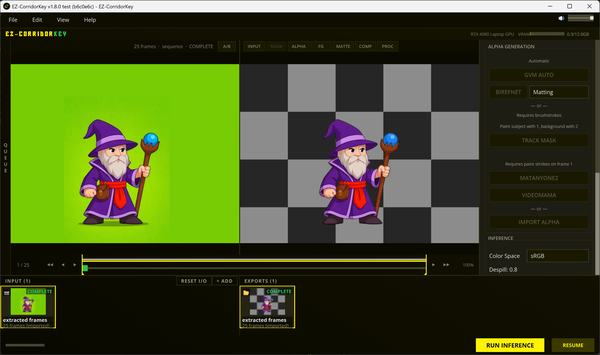
На моём ноутбуке с 4080 все эти уточняющие проходы для 25 кадров занимают минут 3-4.
Кадры качественно очищаются от зелёного фона
EZ-CorridorKey сохраняет изображения в exr, для дальнейшей обработки можно перегнать их в png (вайб-кодим преобразование в s-rgb):
import os
import OpenEXR
import Imath
import numpy as np
from PIL import Image
INPUT_DIR = "."
OUTPUT_DIR = "png_out"
os.makedirs(OUTPUT_DIR, exist_ok=True)
def read_exr(exr_path):
exr_file = OpenEXR.InputFile(exr_path)
header = exr_file.header()
dw = header["dataWindow"]
width = dw.max.x - dw.min.x + 1
height = dw.max.y - dw.min.y + 1
channels = header["channels"].keys()
pt = Imath.PixelType(Imath.PixelType.FLOAT)
def read_channel(name):
return np.frombuffer(
exr_file.channel(name, pt),
dtype=np.float32
).reshape((height, width))
r = read_channel("R") if "R" in channels else None
g = read_channel("G") if "G" in channels else None
b = read_channel("B") if "B" in channels else None
a = read_channel("A") if "A" in channels else None
if r is None:
raise RuntimeError("No RGB channels found")
return r, g, b, a
def linear_to_srgb(x):
return np.where(
x <= 0.0031308,
12.92 * x,
1.055 * np.power(np.clip(x, 0.0, None), 1.0 / 2.4) - 0.055
)
def exr_to_png(src_path, dst_path):
r, g, b, a = read_exr(src_path)
rgb = np.stack([r, g, b], axis=-1)
rgb = np.nan_to_num(rgb, nan=0.0, posinf=1.0, neginf=0.0)
rgb = np.clip(rgb, 0.0, 1.0)
rgb = linear_to_srgb(rgb)
rgb8 = (rgb * 255).astype(np.uint8)
if a is not None:
alpha = np.nan_to_num(a, nan=0.0)
alpha = np.clip(alpha, 0.0, 1.0)
alpha8 = (alpha * 255).astype(np.uint8)
rgba = np.dstack([rgb8, alpha8])
img = Image.fromarray(rgba, mode="RGBA")
else:
img = Image.fromarray(rgb8, mode="RGB")
img.save(dst_path)
def main():
for filename in os.listdir(INPUT_DIR):
if filename.lower().endswith(".exr"):
src = os.path.join(INPUT_DIR, filename)
dst = os.path.join(
OUTPUT_DIR,
os.path.splitext(filename)[0] + ".png"
)
try:
exr_to_png(src, dst)
print(f"Converted: {filename}")
except Exception as e:
print(f"Failed: {filename} ({e})")
if __name__ == "__main__":
main()Коррекция кадров анимации#
Следующий шаг — выбросить лишние кадры (если в анимации есть повторяющие кадры-“замирания”), плохие кадры или пустые, и подтюнить время каждого кадра (при нерегулярном выбрасывании кадров). Также нужно подобрать подстроить loop — стыковку первого и последнего кадра, для недлинных анимаций несложно.
Пример, редактор sorceress за 45$ (или навайбкодить и самому).
На этом шаге должен получиться json с описанием анимации, который вместе с кадрами можно запихать в какой-нибудь движок или сделать гифку и порадоваться.
В анимации видно, что вокруг изображения всё равно есть небольшой ореол некрасивых пикселей на границе, на следующем шаге можно убрать и его
Выделение фич#
В текущем виде атлас спрайтов для анимации в 25 кадров спрайта с bbox-ом в ~225x300 пикселей займет 1948x1386 пикселей.
Попробуем его уменьшить (а также убрать артефакты с краёв и добавить возможность обработать похожие фичи и исключить их)
Для выделения частей изображения можно использовать SAM-3 от Meta. Модель скачивается и запускается локально и умеет находить на изображениях и видео части по текстовому описанию, а также подсказке в виде грубого bbox-а, заданного вручную или полученного из предыдущих кадров, а также расширять или исключать найденные зоны (похоже на инструмент magic wand в photoshop, только тут он намного более MAGIC).
Работа по выделению частей состоит из двух этапов. На первом прописываем части изображения, которые хотим отделить, на одном из кадров (текстом + опционально выделением примерной зоны)
image_path = f"frame_000001.png"
image = Image.open(image_path).convert("RGB")
width, height = image.size
processor = Sam3Processor(model, confidence_threshold=0.5)
inference_state = processor.set_image(image)
processor.reset_all_prompts(inference_state)
inference_state = processor.set_text_prompt(state=inference_state, prompt="robe and belt")
img0 = Image.open(image_path)
plot_results(img0, inference_state)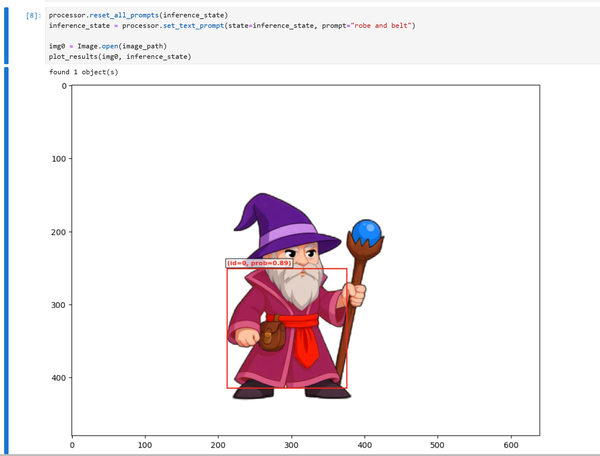
На втором загружаем все кадры в видеокарту с подготовленными промтами и батчингом (в зависимости от количества памяти на gpu, можно запихивать по 4-8 кадров для одновременной обработки).
import os
from pathlib import Path
import numpy as np
from PIL import Image
import torch
import sam3
from sam3 import build_sam3_image_model
from sam3.train.data.collator import collate_fn_api as collate
from sam3.model.utils.misc import copy_data_to_device
from sam3.train.transforms.basic_for_api import (
ComposeAPI,
RandomResizeAPI,
ToTensorAPI,
NormalizeAPI,
)
from sam3.eval.postprocessors import PostProcessImage
from sam3.train.data.sam3_image_dataset import (
InferenceMetadata,
FindQueryLoaded,
Image as SAMImage,
Datapoint,
)
# --------------------------------------------------
# Настройки
# --------------------------------------------------
image_paths = [
"frame_000021.png",
"frame_000022.png",
"frame_000023.png",
"frame_000024.png",
"frame_000025.png",
]
prompts = [
"robe",
"belt",
"head",
"hat",
"hand",
"shoe",
"wooden staff",
"ball",
"bag"
]
out_dir = "parts_out"
os.makedirs(out_dir, exist_ok=True)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
transform = ComposeAPI(
transforms=[
RandomResizeAPI(
sizes=1008,
max_size=1008,
square=True,
consistent_transform=False,
),
ToTensorAPI(),
NormalizeAPI(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]),
]
)
postprocessor = PostProcessImage(
max_dets_per_img=-1,
iou_type="segm",
use_original_sizes_box=True,
use_original_sizes_mask=True,
convert_mask_to_rle=False,
detection_threshold=0.5,
to_cpu=False,
)
GLOBAL_COUNTER = 1
def create_empty_datapoint():
return Datapoint(find_queries=[], images=[])
def set_image_to_datapoint(datapoint, pil_image):
w, h = pil_image.size
datapoint.images = [SAMImage(data=pil_image, objects=[], size=[h, w])]
def add_text_prompt(datapoint, text_query):
global GLOBAL_COUNTER
assert len(datapoint.images) == 1, "Please set image first"
h, w = datapoint.images[0].size
query_id = GLOBAL_COUNTER
datapoint.find_queries.append(
FindQueryLoaded(
query_text=text_query,
image_id=0,
object_ids_output=[],
is_exhaustive=True,
query_processing_order=0,
inference_metadata=InferenceMetadata(
coco_image_id=query_id,
original_image_id=query_id,
original_category_id=1,
original_size=[h, w],
object_id=0,
frame_index=0,
),
)
)
GLOBAL_COUNTER += 1
return query_id
# --------------------------------------------------
# Формирование batched datapoints
# --------------------------------------------------
# Будем хранить:
# 1) transformed datapoints для collate
# 2) маппинг query_id -> (image_path, prompt)
# 3) оригинальные RGBA изображения для сохранения масок
datapoints = []
query_map = {}
rgba_images = {}
for image_path in image_paths:
print(f"Prepare datapoint: {image_path}")
img_rgb = Image.open(image_path).convert("RGB")
img_rgba = Image.open(image_path).convert("RGBA")
rgba_images[image_path] = img_rgba
dp = create_empty_datapoint()
set_image_to_datapoint(dp, img_rgb)
for prompt in prompts:
query_id = add_text_prompt(dp, prompt)
query_map[query_id] = {
"image_path": image_path,
"prompt": prompt,
}
dp = transform(dp)
datapoints.append(dp)
# --------------------------------------------------
# Один batched forward на весь список изображений
# --------------------------------------------------
with torch.inference_mode():
batch = collate(datapoints, dict_key="dummy")["dummy"]
batch = copy_data_to_device(batch, device, non_blocking=True)
# В официальном batched guide inference делается именно так.
output = model(batch)
processed_results = postprocessor.process_results(output, batch.find_metadatas)
# --------------------------------------------------
# Сохранение результатов
# --------------------------------------------------
saved_count = 0
for query_id, meta in query_map.items():
image_path = meta["image_path"]
prompt = meta["prompt"]
if query_id not in processed_results:
print(f"Missing result for query_id={query_id} | {image_path} | {prompt}")
continue
result = processed_results[query_id]
# Обычно тут есть masks / boxes / scores как и в plot_results-примерах.
masks = result.get("masks", None)
scores = result.get("scores", None)
if masks is None or len(masks) == 0:
print(f"No detections: {image_path} | {prompt}")
continue
base = sanitize_filename(prompt)
stem = Path(image_path).stem
image_rgba = rgba_images[image_path]
# Сохраняем все найденные маски по данному prompt
for i in range(len(masks)):
out_path = os.path.join(out_dir, f"{stem}_{base}_{i}.png")
ok = save_masked_part_fullsize(
image_rgba=image_rgba,
mask_tensor=masks[i],
out_path=out_path,
draw_bbox=False,
premultiply_rgb=True,
dilate_pixels=0
)
if ok:
score_text = ""
if scores is not None and len(scores) > i:
try:
score_text = f" | score={float(scores[i]):.3f}"
except Exception:
score_text = ""
print(f"Saved {image_path} | {prompt}[{i}] -> {out_path}{score_text}")
saved_count += 1
print(f"Done. Saved files: {saved_count}")После обнаружения частей, здесь делается небольшая пост-обработка маски — делаем небольшое расширение маски в те стороны, где есть ненулевая альфа, добавляем размытие, и делаем alpha-premultiply. За счёт этого края фич будут сглаженными.

Слева - найденная фича без дополнительной обработки. Справа - исходный кадр. Посередине — кадр со сглаженными фичами. По клику на изображение — полный размер.
Паковка атласа#
Разобранное на части изображение можно запаковать в атлас более плотно ]
]
1572x1636, выигрыш ~5%, но открывает возможность для следующих этапов оптимизации
Удаление похожих кадров фич#
Дальше можно посмотреть на анимацию отдельных фич.
Для лица практически все кадры уникальны:
Но для фич типа поясной сумки на самом деле анимация показывает только её небольшое покачивание вокруг pivot-точки (на некоторых кадрах сумка была перекрыта рукой):
Также с шаром от посоха (pivot-точка находится за пределами самого шара в центре посоха):
Для таких фич уникальные кадры можно было бы заменить на описание вида “кадр 0 + pivot-точка + матрица трансформации”, чтобы оставить в атласе только один кадр для спрайта сумке. В традиционной анимации это делает художник в программах для 2d анимации вроде Spine или Spriter Pro. Найти модель, которая сделала бы это автоматически, мне пока не удалось, только достаточно точно разметить похожие изображения с помощью OpenCV, что могло бы быть использовано как хинт ИИ-модели или художникам. При этом выдаётся степень похожести, и предположительные преобразования translate-rotate-scale, но этого недостаточно для точной замены.
Для фичи шара также существует несколько отдельных уникальных кадров — для создания анимационного приёма растягивания при движении (“нахлёст”), а также при перемещении блика на шаре. Дорисовка таких кадров в скелетную/перекладную анимацию — известный среди аниматоров приём Дракон, попугай и пони. Flash characters, который достигается переключением видимости группы изображений в ходе анимации.
Другим бонусом от описания фич в виде последовательности аффинных преобразований является возможность блендинга между ключевыми кадрами одной или нескольких анимаций.
Так что, возможно, удаление похожих фич — это тема для отдельной статьи.
Вид в движке#
Пока остановился на том, что запихал полученный cut-out спрайт в EdenSpark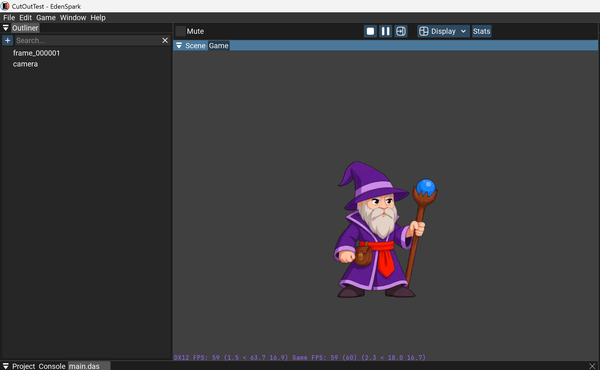
Как промежуточный вывод статьи. В том, что игры, которые используют AI-generated графику сейчас выглядят как говно, виноваты не принципиальные ограничения моделей, а криворукие авторы, которые шлёпают графику одним промптом, не особо разбираясь тем, как сделать её нормально.