Малость нырнул в кучу статей про асинхронность и корутины в различных языках. Напишу небольшую выдержку (с переводами примеров на daScript там, где актуально), о том, что корутины можно начинать рассматривать как расширение возможностей итераторов и колбеков (функторов), а не с более часто встречающейся генерации последовательностей или реализации паттерна “продюсер-консюмер”.
Ссылки
[1] Iterators Inside and Out - обзор итераторов в различных языках, для каких задач удобны
[2] Iterators Inside and Out. Part 2 - подводка к тому, что абстракция итераторов требует примитивов работы с параллельным кодом
[3] Well Done: A Sentinel Value - каналы
[4] Итератор: внутрь и наружу - совсем краткий вывод из статей [1] и [2], и дополнения в комментариях
[5] Паттерны использования «call with current continuation» - перевод статьи про паттерны использования call with continuations в Lisp, среди которых — реализация корутин
[6] Журнал “Практика функционального программирования”. Статья “Продолжения на практике” - пример “выворачивания” внутреннего итератора во внешний
[7] The building blocks of Ruby - особенности блоков в Ruby, нелокальные возвраты из итераторов
[8] General ways to traverse collections - обзоры способов обхода коллекций, примеры на Scheme. Итератор с памятью (стейт-машина) в функциональном стиле
[9] Towards the best collection API - пример “выворачивания” итераторов на Scheme
[10] Yield: Mainstream Delimited Continuations - yield в разных языках. Delimited continuations
[11] Introduction to Programming with Shift and Reset - операторы shift и reset
[12] Ideas for a Programming Language Part 2: A more liberal call stack - про недостатки абстракции стека вызовов
[13] Coroutines in C - классическая статья про проблемы реализации корутин в C. Трюк с реализацией корутин с помощью метода Даффа
[14] C++ Coroutines Do Not Spark Joy - обзор реализации корутин в стандарте C++
[15] My tutorial and take on C++20 coroutines - ещё одна статья про корутины в C++ 20, трюк с хранением результата корутины на стеке через Promise Object
[16] CppCoro - A coroutine library for C++ - библиотека обёрток над корутинами из стандарта C++
[17] CppCon 2016: Gor Nishanov “C++ Coroutines: Under the covers” - доклад про реализацию корутин в стандарте C++, особенности реализации генерируемого кода в LLVM, возможности по оптимизации кода на уровне LLVM. Хорошо для понимания того, когда возможна элиминация выделения памяти. LLVM coroutines - интринсики для корутины в LLVM.
[18] Handmade Coroutines for Windows - альтернативные реализации корутин для windows. Раз C++ не даёт прямого доступа к указателю на стек, можно подменить его на ассемблере
[19] Implementing coroutines with ucontext - реализация корутин через posix ucontext
[20] Boost::Context - реализации переключения контекста из boost. Используют обёртки над posix или платформенные заголовки для переключения контекста, или ассемблерный трюк из gcc (особенности реализации)
[21] call/cc (call-with-current-continuation): A low-level API for stackful context switching - пропозал по добавлению в стандарт c++ функционала call/cc
[22] Goroutines - горутины из go, управляются рантаймом языка. Tour of Go. Goroutines. Планировщик горутин кооперативный, но “ощущается”, как вытесняющий
[23] Concurrency Patterns In Go - каналы, оператор select выбора из нескольких каналов
[24] Kotlin coroutines. async/await - многопоточные async/await в Kotlin. Идиомы future/promise, async/await/deferred
[25] What Color is Your Function? - проблемы с комбинированием синхронных и асинхронных функций
[26] What is Zig’s “Colorblind” Async/Await? - необычный подход Zig, трансформация синхронных функций в асинхронные и наоборот
[27] Zyg’s Async - Async в Zig (документация)
Внешние итераторы#
Внешний итератор — объект, реализующий некоторый интерфейс Iterator (C#, Python), у которого есть методы получения первого элемента коллекции (метод у коллекции или свободная функция), перехода на следующий элемент, и проверки на то, есть ли ещё элементы. На шаблонах C++ — явного интерфейса нет, но есть протокол, описывающий способы описания итератора для своих типов.
Рассматривается в книге Банды Четырёх. В [8] критикуется название за активный суффикс -or, хотя методы итератор зовёт внешний код, предлагается название iteratee. Итераторы в стиле C++ также называют курсорами.
Итераторы в daScript:
var it <- each ([[int 1;2;3;4;5]]) //создание итератора
var x : int
while next(it, x) // получение следующего значения
print("x = {x}\n")
verify(empty(it)) // функция проверки проверки существования следующего значенияЧасто в языках есть синтаксический сахар для того, чтобы записывать выражение выше как for-each цикл:
var it <- each ([[int 1;2;3;4;5]])
for x in it
print("x = {x}\n")Элегантно решаемая внешним итератором задача:
Поиск элемента
//TT - generic-тип, TT-& - "убрать из определения типа символ ссылки"
def find(it: iterator<auto(TT)>; value:TT-&)
for x in it
if x == value { return true; }
return falseБолее неаккуратное решение
Проверка двух коллекций на равенство
(и эквивалентные задачи, требующие поочередного обращения к двум или более коллекциям — функция zip; итератор выдающий по очереди элементы каждой коллекции)
def is_equal(it1, it2: iterator<auto(TT)>)
var i2: TT-&
var it2Ended: bool
for i1 in it1 //обращение к первому итератору
it2Ended = next(it2, i2) //обращение ко второму итератору
if !it2Ended || (i1 != i2)
return false
return !next(it2, i2)Неэлегантный пример
Итератор в дереве
Рекурсивная функция печати дерева на экран занимает 4 строки
struct Tree
data: int
left, right: Tree?
def printTree(a: Tree?)
if a != null
printTree(a.left)
print("{a.data}\n")
printTree(a.right)
...
let tree = new [[ Tree
data = 5,
left = new [[Tree
data = 1
]],
right = new [[Tree
data = 7,
right = new [[Tree
data = 10
]]
]]
]]
printTree(tree)Попробуем написать итератор для дерева. Строительным блоком для кастомных внешних итераторов в daScript служат лямбда-функции.
struct IterateState
tree: Tree?
step: int
var stack: array<IterateState?>
stack |> push(new [[IterateState tree = tree]])
unsafe
let treeIterator <- @ <| (var current: int&) : bool
var hasValue = false
while !empty(stack) && !hasValue
var state = back(stack)
if state.step == 0
state.step = 1
if (state.tree.left != null)
push(stack, new [[IterateState tree = state.tree.left]])
elif state.step == 1
state.step = 2
current = state.tree.data
hasValue = true
else
pop(stack)
if (state.tree.right != null)
push(stack, new [[IterateState tree = state.tree.right]])
return hasValue
for v in each(treeIterator)
print("{v}\n")Можно также написать итератор в ООП стиле, определив класс в C++ и перегрузив функцию isIterable, но пример в ООП-стиле есть в [1], он там занимает также занимает 50 строк.
На daScript получилось 26, но всё равно, как, во имя Святой Матери Тьюринга, из четырёх-строчной рекурсивной функции получилась такая каша?
Колстек#
Часть работы в функции printTree за нас выполнила скрытая структура данных, callstack.
Во время рекурсивного первого рекурсивного вызова программа кладёт в стек адрес возврата, и осуществляет вызов этой функции, затем проделывает работу по вызову “полезной нагрузки” (print). После чего в следует второй рекурсивный вызов.
Если на собеседовании у вас спросят, какая у вас любимая структура данных, смело отвечайте “стек вызовов”, и рассказывайте про то, как было бы плохо писать программы без него
Если внимательно посмотреть на структуру функции treeIterator, можно заметить, что она выполняет те же шаги, в той же последовательности!
def printTree(a: Tree?)
//step 0 - кладём в стек адрес возврата, и начинаем новую итерацию вызова функции
printTree(a.left)
//step 1 - выполняем "полезную нагрузку"
print("{a.data}\n")
//step 2 - кладём в стек адрес возврата
printTree(a.right)
//невидимый
//step 3 - ..выходим из функции, удаляем из стека верхнее значение, возвращаемся выше по стекуМожно заметить небольшое различие на шаге 2 — в реализации printTree сначала происходит второй рекурсивный вызов, и затем возврат из основной функции, а в treeIterator значение сначала удаляется из стека, а затем в него кладётся новое. Это похоже на то, как происходит tail call optimization — вместо того, чтобы положить в стек второе значение, а потом удалить и два верхних значения, мы сразу же удаляем ненужный более адрес возврата, т.е. выполняем step3, еще до step2.
Также функция printTree приостанавливается в точках 0 и 2, на момент вызова подпрограммы, и продолжает выполнение после возврата из подпрограммы. Это вторая крутая возможность, которую предоставляет колстек, и о которой при программировании обычно даже не задумываются. Однако при кастомной реализации итератора мы сталкиваемся с тем, что без каких-либо особых трюков приостановить выполнение функции и продолжить его с того же места невозможно. Вместо этого приходится эмулировать паузы с помощью конечного автомата, реализуемого с помощью цикла и переключения пути выполнения изменением переменной state.
Собственно, большинство идей, связанных с сопрограммами (википедия напоминает, что ни в коем случае не следует путать их с копрограммами!), так или иначе связаны с тем, чтобы предоставить нам возможность приостанавливать выполнение функции и продолжать его.
Уже может стать понятно, что для этого язык должен каким-либо образом предоставить языковые конструкции, которые позволили бы нам не определять переменную var stack: array<IterateState?> явно, а “отдавать команду” положить туда что-то неявно, в идеале так же прозрачно, как это происходит в момент вызова функции.
Также стоит обратить внимание на то, где выделяется и хранится эта переменная. Здесь это просто локальная переменная, захваченная лямбда-функцией, но перед компилятором при реализации сопрограмм стоит серьёзная задача — где разместить этот “другой” стек. С одной стороны — его можно выделить в куче, чтобы он мог “пережить” область создания итератора, с другой — такая аллокация замедляет создание сопрограмм.
В общем-то, практически все отличия в реализации сопрограмм в разных языках сводятся к тому, чтобы различными способами решить эти вопросы — где и как будут выделяться “другие стеки”, и каким образом к ним можно обращаться из языка. Различных подходов много, и они имеют свои плюсы и минусы. Если с этого момента прояснилось, можно походить по ссылкам, заглянуть, кто что придумал в различных языках. Впрочем, можно снова зависнуть где-нибудь на Лиспе, или языках с ленивыми вычислениями.
Но пока вернёмся к колстеку — стоит ещё раз сравнить функции printTree и более общую treeIterator, и помедитировать на способ, которым сделано обобщение. Такое представление “невидимого” в коде колстека в явном виде называется реификацией.
Внутренние итераторы#
Внутренний итератор — функция-callback, которая передаётся в функцию обхода коллекции.
Итерация разделяет код на 2 части: (1) код ответственный за генерацию серии объектов, и (2) код, который выполняет над переданным ему объектом некоторую операцию. Для внешних итераторов это (1) тип, который может реализовывать протокол итерации и (2) тело цикла обхода. В этом стиле (2) является главным, он решает, когда запросить следующее значение, или когда прекратить итерации. Внутренние итераторы выворачивают всё наизнанку. Код, который генерирует значения, решает, когда ему вызвать переданный ему колбек.
Внешние функции, перебирающие значения, могут быть реализованы как методы объекта (array.each в Ruby), или generic-функции (std::find_if в C++)
Элегантно решаемые внутренними итераторами задачи:
Итерация по дереву
def each(var tree:Tree?; blk:lambda<(what: int):void>)
if (tree.left != null) { each(tree.left, blk); }
invoke(blk, tree.data)
if (tree.right != null) { each(tree.right, blk); }
tree |> each() <| @(value: int)
print("{value}\n")Отлично, в 3 строчки.
Поиск элемента
Возьмём общий внутренний генератор map из стандартной-библиотеки functional функцию поиска индекса элемента в массиве по условию (это синтетический пример, в модуле buildin есть более эффективная реализация этой функции)
def my_find_index_if(var arr: iterator<auto(TT)> explicit; blk:lambda<(what:TT -&):auto(QQ)>)
for value, i in map(arr, blk), range(INT_MAX)
if value
return i
return -1
//using
var it <- each ([[int 0;1;2;3;4]])
var answer = it |> my_find_index_if <| @(value: int)
print("check: {value}\n")
return value > 1
print("{answer}\n")
//output
check: 0
check: 1
check: 2
2Здесь таится интересный момент, связанный с прерыванием итерации. Почему функция map не выполнила проверку 3 и 4 элемента массива? Каким именно образом функция map “узнала”, что нужно остановить итерацию?
Если вы попробуете реализовать функцию find_index с помощью std::for_each в C++, то стокнётесь в проблемой, что return не может остановить итерацию for_each.
std::vector<int> myvector = {0,1,2,3,4};
int find_index(std::vector<int>& myvector, std::function<bool(int)> checker) {
int answer = -1;
bool answerFound = false;
auto fn = std::for_each(myvector.begin(), myvector.end(), [&](int i) {
std::cout << "check:" << i << std::endl;
if (!answerFound) {
if(checker(i)) {
answer = i;
answerFound = true;
return; //невозможно остановить выполнение for_each
}
}
});
return answer;
}
//
int main() {
std::cout << find_index(myvector, [](int i) {
return i > 1;
});
}
std::cout << find_index(myvector);
//Output
check:0
check:1
check:2
check:3
check:4
2Что именно мешает лямбда-функции, переданной в for_each прекратить итерацию? Ответ - колстек, а точнее стекфрейм функций. В момент вызова лямбда-функции внутри for_each он выглядит так:
main
find_index
for_each
стекфрейм for_each
for_each_lambda
checker_lambdafor_each как и любая функция, может выделить себе дополнительную память на стеке под свои нужны, и если for_each_lambda или checker_lambda захотят выйти на уровень выше for_each, им нужно уметь раскручивать стек (скорее всего, конкретно для for_each там ничего нет, но сама необходимость раскрутки всего, что находится между функциями разного уровня на стеке блокирует возможность выхода)
Конечно, раскручивать стек в C++ умеют исключения, но… просто посмотрите на этот код и никогда так не делайте:
int find_index(std::vector<int>& myvector, std::function<bool(int)> checker) {
try {
auto fn = std::for_each(myvector.begin(), myvector.end(), [&](int i) {
std::cout << "check:" << i << std::endl;
if(checker(i)) {
throw i; //"выбрасываем" ответ из foreach
}
});
}
catch (int throwedAnswer) {
return throwedAnswer;
}
return -1;
}Возможность раскручивать стек называется non-local returns и присутствует в языках типа Ruby (пример в [1]) или Kotlin [24]:
val list = listOf(1, 2, 3, 4, 5)
val value = 3
var result = ""
list.forEach {
result += "$it"
if (it == value)
return@forEach //выход из foreach
}
//result="123"Другой более универсальный подход, реализованный в daScript и других языках с поддержкой генераторов — приостанавливать выполнение map/for_each и передавать промежуточные результаты “вовне”, с возможностью по желанию прекратить приостановленную итерацию на уровень выше (генераторы также известны как “елды” среди добравшихся до Unity артистов).
Совсем нехороший пример
Проверка двух коллекций на равенство
Без задействования генераторов, корутин, потоков или продолжений, или других способов приостановить функцию, не пишется. Мешают, как и в предыдущем примере, всё те же стекфреймы в колстеке. Но если в примере с ранним выходом из внутреннего итератора удавалось хотя бы выкрутиться хаком и “выпрыгнуть” с помощью исключений, необратимо раскрутив стек, то здесь для приостановки каждой из двух функций-колбеков нужно хранить оба состояния обеих функций.
Генераторы#
Генераторы — это возобновляемые функции. Возвращаемый тип генератора — итератор (гибрид между внутренним и внешним)
let gen <- generator<int>() <| $()
for t in range(0,10)
yield t
return falsemap, как и большинство функций из модуля functional в daScript, возвращают генераторы, так что с помощью неё должно быть возможно (хотя и не нужно) реализовать проверку двух коллекций на равенство, недоступную для внутренних итераторов в языках без поддержки генераторов:
def is_equal(var it1, it2: iterator<auto(TT)>)
unsafe
var equalResult = true
//один из генераторов возвращает значения из коллекции
var aGenerator <- it1 |> map <| @(aValue:TT-&)
return aValue
//второй генератор берёт значение из второй коллекции и сравниваем со значением из другого генератора
//лямбда-функция захватывает первый генератор для получения значений из него
var bGenerator <- it2 |> map <| @ [[&aGenerator]](bValue:TT-&)
var aValue : TT-&
if !next(aGenerator, aValue)
return false
print("{bValue} {aValue}\n")
return bValue == aValue
//продолжаем брать из генераторов значения, пока она эквивалентны
while equalResult && next(bGenerator, equalResult)
pass
//коллекции эквивалентны, если оба итератора обработали все значения
var aLast : int
return !next(aGenerator, aLast) && empty(bGenerator)Двунаправленные генераторы
Python поддерживает также отправку данных генератору из вызывающего кода
>>> def double_inputs():
... while True:
... x = yield
... yield x * 2
...
>>> gen = double_inputs()
>>> next(gen)
>>> gen.send(10)
20
>>> next(gen)
>>> gen.send(6)
12Разворачивание итераторов#
Теперь рассмотрим возможность “выворачивания” итераторов. К примеру, у нас есть “красивая” версия внутреннего итератора each для дерева, и функция сравнения, принимающая внешние итераторы, в которую хочется передать итератор обхода дерева.
Для начала посмотрим, как можно передать значения из лямбда функции “наружу”, с помощью захвата в замыкание (closure) лямбда-функции:
def to_array(var tree : Tree?)
unsafe
var arr: array<int>
//захватываем arr в замыкание по ссылке
each(tree) <| @[[&arr]](value: int)
arr |> push(value)
return <- arrФункция накапливает все значения в переменной arr и возвращает полностью собранный массив. Следующим шагом попробуем избавиться от этого накопления и вернуть управление вызывающему коду, как только будет получено следующее значение из each. Но тут возникает следующая проблема. Если each не спроектирована так, чтобы её можно было останавливать, то её и невозможно будет остановить из колбека. Т.е. нам нужна другая функция each_async, которая будет возвращать значение через генератор yield.
def each_async(tree:Tree?) : iterator<int>
return <- generator<int>() <| $ ()
if tree.left != null
for newVal in each_async(tree.left)
yield newVal
yield tree.data
if tree.right != null
for newVal in each_async(tree.right)
yield newVal
return false
var eq = is_equal(each_async(tree1), each_async(tree2))Чуть менее компактно, чем первоначальная версия, за счёт того, что из вложенных генераторов приходится доставать данные с помощью дополнительных циклов обхода (yield должно возвращать int, а вложенный генератор возвращает iterator<int>, из которого нужно достать данные для выдачи внешнему генератору).
Python и некоторые другие языки поддерживают делегацию генераторов — синтаксический сахар, который позволяет избежать написания таких циклов
def concat(a, b):
#for item in walkFirst(a): yield item
#"берём значение из генератора и передаём дальше
yield from walkFirst(a)
def walkFirst(a):
for item in a: yield itemupdate
Аналогичный макрос yield_from для daScript
Но тут есть важный момент, снова возвращающий нас к колстекам. Делегация генераторов — это просто синтаксический сахар, но мы не можем написать возврат значения из вложенных функций, не прокидывая эту делегацию через каждый уровень вложенности. Чтобы полноценно выйти на несколько уровней вверх, в затем вернуться, нам потребуется структура, которая реифицирует не один уровень стека, а весь стек. Следующий пример на ruby показывает такую структуру.
Файберы#
В [2] есть пример разворачивания итераторов из Ruby:
class MyEnumerator
include Enumerable
def initialize(obj)
@fiber = Fiber.new do # Spin up a new fiber.
obj.each do |value| # Run the internal iterator on it.
Fiber.yield(value) # When it yields a value, suspend
# the fiber and emit the value.
end
raise StopIteration # Then signal that we're done.
end
end
def next
@fiber.resume # When the next value is requested,
# resume the fiber.
end
endYield происходит прямо из each во внешнюю функцию! Если обратиться к предыдущим замечаниям про колстеки, то здесь будет:
eachдля дерева создаёт стек, в котором хранит адреса возвратом рекурсивных вызовов- метод
nextполностью “замораживает” этот стек, и переключается на другой, в управляющем коде.
Так что Fiber здесь — структура, которая реифицирует не только фрейм стека, как генераторы, но весь стек полностью.Файберы имеют свой стек и копии локальных переменных. Один выполняются в одном потоке, и передача управления между ними управляется кодом пользователя — пока один файбер не передаст управление следующему, переключения не будет.
Файберы — своеобразная “точка связи” итерации с параллелизмом.
Функции без стекфрейма#
В [12] рассматриваются альтернативы хранению временных переменных функции в стеке. В качестве примера рассматривается создание языков для визуального программирования типа Kismet/Blueprint из Unreal. Каждая функция-строительный кирпич заранее выделяет необходимую ей память и просто использует её повторно, если вызывается вновь. Если нужно вызвать функцию дважды — выделяется два блока памяти. Преимущество такого подхода — можно легко связывать цепочки функций вида “пойти в точку А, подождать секунду, затем проиграть анимацию и звук одновременно”.
Чтобы создать код связи нод на C++, может потребоваться код вида:
bool bMoved = false;
CompareBoolNode * cmp = new CompareBoolNode(bMoved);
DelayNode * first_delay = new DelayNode(some_hardcoded_number);
DelayNode * second_delay = new DelayNode(another_hardcoded_number);
DelayNode * third_delay = new DelayNode(a_third_hardcoded_number);
MatineeNode * matinee = new MatineeNode(Matinee_0, Interior_Elevator_3);
BoolNode * set_moved = new BoolNode(bMoved, true);
BoolNode * clear_moved = new BoolNode(bMoved, false);
cmp->onFalse += &first_delay->start
first_delay->onFinished += &matinee->play;
matinee->onCompleted += &second_delay->start;
second_delay->onFinished += &matinee->reverse;
second_delay->onFinished += &set_moved->in;
set_moved->out += &third_delay->start;
third_delay->onFinished = &clear_moved->in;
RTriggerVolume_0.onTouched += &cmp->in;При этом, на самом деле программист хотел бы написать этот же код, в таком виде:
bool bMoved = false;
RTriggerVolume_0.Touched = [bMoved]() mutable {
if (bMoved)
return;
Delay(some_hardcoded_delay);
Matinee_0.Play(Interior_Elevator_3);
Delay(another_hardcoded_delay);
bMoved = true;
Matinee_0.Reverse(Interior_Elevator_3);
Delay(a_third_hardcoded_delay);
bMoved = false;
}; Проблема в том, что в C++ сложно нет функции Delay. Файберы могут помочь с её реализацией, но иметь отдельный стек для каждой мелкой сопрограммы может быть дорого. Вместо этого компиляторы визуальных языков могут подсчитать, сколько памяти потребуется для всего скрипта, и выделить ему это весь этот блок целиком. Таким образом, во время выполнения нет аллокаций. Это не особо влияет на скорость, но влияет на то, все функции такого языка могут быть в любой момент прерваны и возобновлены — функции без фреймов на стеке не страдают от того, что кто-то другой перехватывает управление.
Корутины в C++#
Реализация замаскированным конечным автоматом
В [13] приведён хак-пример с тем, чтобы реализовать корутины с ограничениями на макросах с помощью объединения цикла и switch (грязный трюк, названный метод Даффа).
Реализации корутин в виде платформо-зависимых библиотек
Серьёзные реализации, использующие трюки на ассемблере или ucontext — [18] и [19] от Malte Skarupke и [20] Boost::Context от Oliver Kowalke. От него же, реализации coroutine2(с выделением стеков на хипе, и first-class продолжениями) и fiber (отличия между ними, файбер здесь — green thread, поток, управляемый диспетчером. Файберы “живут” в одном кернел-треде. Ключевое отличие - корутины передают управление друг другу, буст-файберы — планировщику).
Бекграунд для реализации буст библиотек — переключатели контекста (через примитив call/cc из Boost::Context).
- fcontext_t - переключение асм-кодом (самое быстрое)
- ucontext_t и WinFiber - в 10-100 раз более медленное переключение с использованием функций ядра ОС
Хороший ответ на вопросы из собеседований вроде “зачем может потребоваться писать код на ассемблере в 20XX году?”
Корутины из стандарта C++20
В стандарте C++ 20 года реализована минимальная поддержка корутин. Корутины из стандарта, в отличие от boost::coroutine не имеют своего стека (стандарт отделался тем, что заявил “если хотите возвращать управление из вложенных функций — вам нужны файберы, а не корутины”). Также не содержит в std готовых примитивов-паттернов для удобной работы, вариант их реализации можно посмотреть в библиотеке cppcoro [16].
template<class Visitor>
void f(Visitor& v);
//stackfull-корутина с передачей управления, boost::context
asymmetric_coroutine<T>::pull_type pull_from([](asymmetric_coroutine<T>::push_type& yield) {
f(yield);
});
//stackless-корутина, C++ 20
generator<T> pull_from() {
// yield может быть вызвана только отсюда
f(???);
}Можно вернуться к примерам с разворачиванием итераторов на daScript и ruby, и попробовать “спроецировать” их на синтаксис stackful-корутин.
В пропозале по добавлению boost::coroutine в стандарт C++ приведён как раз аналогичный пример с деревом, с явным продолжением-аргументом он выглядит впечатляюще круто:
using ContPush = boost::coroutines::coroutine<std::string>::push_type;
using ContPull = boost::coroutines::coroutine<std::string>::pull_type;
void traverse(tree* n, ContPush& out) {
if (n->left) traverse(n->left, out);
out(n->value);
if( n->right) traverse(n->right, out);
}
tree* tree1 = testCreateTree1(), tree2 = testCreateTree2();
//трансформация внутреннего итератора во внешний
ContPull& iterator1([&](ContPush& out) {
traverse(tree1, out);
});
ContPull& iterator2([&](ContPush& out) {
traverse(tree2, out);
});
//у boost::coroutines::coroutine<std::string>::pull_type есть iterator
bool isEqual = std::equal(std::begin(iterator1), std::end(iterator1), std::begin(itertor2));Stackless-корутины не позволяют таких трюков, так как используют стек вызывающего их кода, но более эффективны.
Benchmark из либы CO2, эмулирующей stackless-корутины (цена вызова корутины):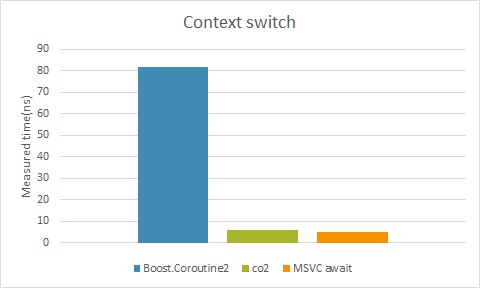
Кроме вызова важна также стоимость создания корутины. В случае с CO2 корутина — это только синтаксический сахар, и код работает быстро (но в этой библиотеки и нельзя “захватить” переменные на стеке в корутину после восстановления). В корутинах из стандарта C++, генерируется код с аллокацией таких данных в куче, и затем компилятор может оптимизировать эти аллокации в случае, если код удастся трансформировать и инлайнить. Сделает он это или нет — неизвестно.
В [14] Malte Skarupke приводит примеры, когда это не работало даже в относительно простых случаях, когда должно быть возможно. Узнать, будет или нет выполнена оптимизация — сложно, а разница в скорости между двумя вариантами — на два порядка, так что часто создавать корутины, полагаясь на то, что будет быстро, без постоянных проверок сгенерированного кода невозможно. Как происходит трансформация кода в LLVM детально рассматривается в [17] (ещё один большой кусок информации, которую должен держать в голове хороший C++ программист). Вдобавок меня пугает то, что такая трансформация требует повторного прохода всех стадий оптимизации (если я правильно понял презентацию, 32:14), время сборки большой программы — больное место языка.
Кому хотелось конкурентности, много лет как запилили себе файберы (чаще всего пулом, чтобы без переаллокаций, и с явным или неявным разбросом по тредам):
Naughty Dog: Parallelizing the Naughty Dog Engine Using Fibers
Multithreading the Entire Destiny Engine
Где-то дочитав досюда можно почитать туториал [15] по корутинам в C++ 20 и посмотреть на libcoro [16].
Различия в терминологии#
Стоит отметить различие в определении файберов в различных языках. В некоторых файберы отличаются от генераторов только тем, что имеют стек. Такую таксономию например предлагает стандарт C++ 20. В других языках файберы может отличать ещё и то, что они передают управление не другому файберу, а диспетчеру, который выбирает, кому передать управление дальше.
Например, boost::coroutine называет корутину со стеком не файбером а stackful coroutine, а fiber — это то же + управление через диспетчер. Я тут встану на сторону C++ 20, потому что для корутин со стеком (файберов), которые вдобавок ещё и управляемые диспетчером, и так придумана куча названий. Встречаются:
- просто корутины (в
luaдля большей путаницы назвали это так) - тасклеты (
Stackless Python, вообще богат на термины) - горутины из
golang([22], [23]), причисляемыми в статьях к файберам, отличаются по функционалу, и могут раскидываться по различным тредам планировщиком задач языка (а следовательно, требуют синхронизации доступа к общим ресурсам), так что должны рассматривать отдельно. - зелёные потоки, протопотоки, микропотоки
На этом закончу первую половину статьи. Вторая будет про диспетчеры, способы блокирования и комбинирования различных корутин между собой.